
 AI中臺
AI中臺 智能硬件
智能硬件 RPA云平臺
RPA云平臺 數智員工
數智員工

 新一代企業數字核心系統(YG-DAP)
新一代企業數字核心系統(YG-DAP) 智稅云
智稅云 財務云
財務云 易審云
易審云 協同云
協同云 人才云
人才云 培訓云
培訓云 知識云
知識云 工程云
工程云 售電云
售電云基于依存句法分析的資金賬戶交易畫像
- 時間:2019-01-15
- 來源:遠光軟件

本文作者:丁德智,李玫,李國棟(遠光軟件股份有限公司)
摘要:為了提升電網企業資金安全管控能力,有效防范資金安全風險,保障資金高效運轉,文章利用企業海量的銀行交易流水數據,應用自然語言處理技術,基于依存句法分析的結果設計摘要標簽化的提取規則,得到與交易記錄有關的交易標簽與業務標簽。進一步構建出動態完整、實時反映的資金賬戶交易畫像,幫助企業管理人員全面了解賬戶的歷史交易行為,及時發現異常交易風險,輔助管理決策。使用某電網公司6個月的資金交易數據對模型的效果進行測試和評估,獲得了平均96%以上的F1值,結果證實了模型具有很好的實用性,能夠在電網企業進行推廣應用。
關鍵詞:賬戶畫像;資金管理;依存句法分析;交易摘要
0 引言
電網企業資金流動大,交易頻繁,屬于典型的資金密集型企業。目前電網企業在資金安全管理方面普遍存在資金監控信息化程度低和監督監控不完善等問題。改變現有監控系統低效、信息孤島的現狀,需要構建基于大數據的集安全監控、信息共享、數據分析、決策支撐為一體的資金智能安全防控平臺,實現信息化的資金安全管理模式。這一管理模式的實現需要使用自然語言處理(Natural Language Processing, NLP)及機器學習等技術。目前NLP技術的研究主要集中于情感分析方面,多應用于互聯網行業。在電力行業,尤其是資金安全管理領域應用存在較多空白。
傳統的資金賬戶畫像主要是基于賬戶的靜態屬性進行標簽分類,存在更新不及時、信息滯后的缺點。本文通過對企業海量的銀行資金交易流水摘要進行句法關系解析,智能提取交易標簽和業務標簽,構建動態、完整、全面的資金賬戶交易畫像,幫助管理人員實時了解賬戶的歷史交易行為,及時洞察賬戶異常動作,精準定位交易風險,為資金賬戶的全面監控和安全使用提供高精準度的風險防控手段。
1 資金賬戶交易畫像提取框架
1.1 整體提取框架
標簽提取流程如圖1所示,提取流程包括數據預處理、自然語言處理、詞庫構建及標簽提取4個步驟。實現思路是先對交易摘要進行預處理,過濾掉噪聲數據,然后進行自然語言處理,解析得到句法關系樹,根據標簽提取規則,從句法關系樹中提取交易標簽和業務標簽。對于提取不成功的摘要,先用交易標簽和業務標簽相互填補,如果仍然存在摘要提取失敗,則將其歸為“未知交易”。
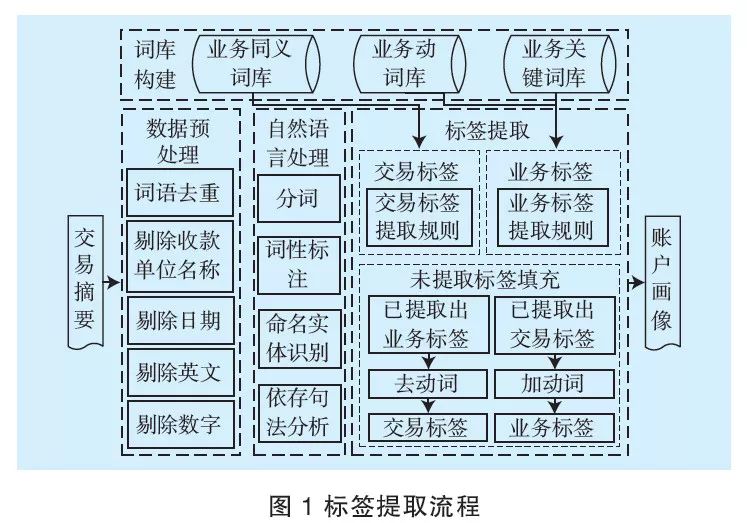
1.2 核心步驟說明
1.2.1 數據預處理
本步驟主要是去重和剔除摘要中的噪聲數據,例如日期、數字、英文及收款單位名稱等,清洗后的摘要只保留了關鍵信息。
示例:“aHYX_付5月購電費(3001)”→“付購電費”。
1.2.2自然語言處理
本步驟利用哈爾濱工業大學的LTP(Language Technology Platform)開源中文NLP系統對預處理后的交易摘要進行分詞、詞性標注、命名實體識別、及依存句法分析,最終生成句法關系樹。
根據摘要的特點,本模型主要用到的句法關系有核心詞(HED)、主謂關系(SBV)、動賓關系(VOB)、并列關系(COO)及狀中關系(ATT)。詳細的語義關系說明請參考語言云簡介。
1.2.3 詞庫構建
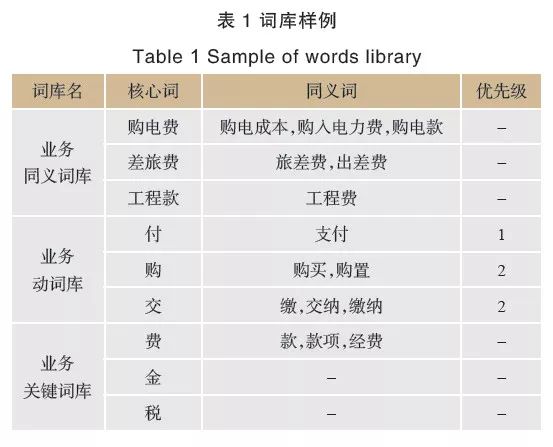
本模型應用到的詞庫有業務同義詞庫、業務動詞庫及業務關鍵詞庫。其中業務同義詞庫用于合并語義相同的交易業務,例如
上述詞庫需要資深業務專家參與構建,本模型詞庫的部分樣例見表1所列。
1.2.4 標簽提取
標簽提取是本模型的核心步驟,包括交易標簽提取、業務標簽提取及未提取標簽填充3部分。
1)交易標簽
根據句法依賴關系樹,按規則提取交易標簽,例如差旅費、購電費等,主要用到了業務同義詞庫,詳細的提取規則見2.1節。
2)業務標簽
根據句法依賴關系樹,按規則提取業務標簽,例如報銷差旅費、預付購電費等,主要用到了業務動詞庫和業務關鍵詞庫,詳細的提取規則見2.2節。
3)未提取標簽填充
對于未能提取交易標簽但提取了業務標簽的摘要,將業務標簽去除與業務動詞庫相匹配的詞,即可獲得交易標簽,例如:
2 基于句法模式的標簽提取規則
2.1 交易標簽提取規則
清洗后的交易摘要基本是短文本,句法關系相對簡單,HED的詞性主要為動詞和名詞,因此交易規則將圍繞HED的詞性進行設計,具體如下。
2.1.1規則1
若HED詞性是名詞(n表示),將HED與業務同義詞庫進行模糊匹配:
1)若匹配出零個標簽,則不能提取交易標簽;
2)若匹配出1個標簽,則此標簽的核心詞為交易標簽;
3)若匹配出多個標簽:若多個標簽對應的核心詞是1個,則此核心詞為交易標簽;若多個標簽對應的核心詞是多個,則利用HED的ATT詞進行過濾:若無ATT,將HED切換為精準匹配,如果能精準匹配出1個,則此標簽的核心詞為交易標簽,否則不能提取標簽;若有多個ATT,根據ATT的順序,依次進行模糊匹配過濾,如果最終核心詞是1個,則此核心詞為交易標簽,否則不能提取標簽。
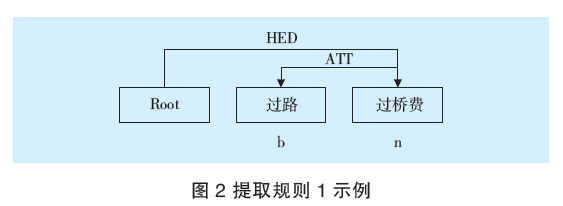
提取規則1示例如圖2所示,示例為提取交易標簽
2.1.2規則2
若HED詞性是動詞(v表示),HED存在VOB詞且詞性是名詞,將VOB詞與業務同義詞庫進行匹配,匹配邏輯與“規則1”一致(如果有多個VOB,則依次按本規則匹配)。
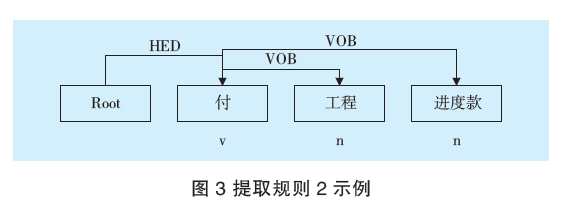
提取規則2示例如圖3所示,示例為提取交易標簽
2.1.3規則3
若HED詞性是動詞,且不存在VOB詞或VOB詞的詞性不是名詞:
1)若HED有COO關系的詞。若該詞的詞性是動詞,則將該詞當作HED,按“規則2”邏輯進行匹配;若該詞的詞性不是動詞,則按“HED無COO關系的詞”的規則處理(如果有多個COO關系,則依次按本規則執行,由于是短文本,基本不存在這種情況)。
2)若HED無COO關系的詞。若HED有ATT關系的詞,將該詞與業務同義詞庫進行匹配,匹配邏輯與“規則1”一致(如果有多個ATT關系的詞,則按句法順序,依次按本規則執行);若HED無ATT關系的詞,但有SBV關系的詞,則將該詞與業務同義詞庫進行匹配,匹配邏輯與“規則1”一致,否則不能提取標簽。
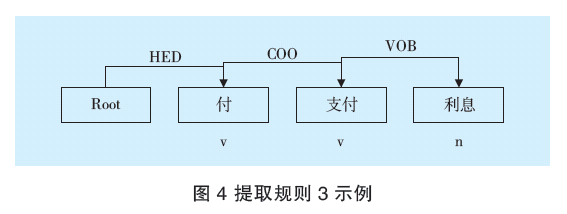
提取規則3示例如圖4所示,示例為提取交易標簽
2.1.4規則4
若HED詞性既不是名詞也不是動詞:
1)若句中只有HED一個詞,將HED與業務同義詞庫進行匹配,匹配邏輯與“規則1”一致;
2)若句中還有其他詞,則不能提取出標簽。
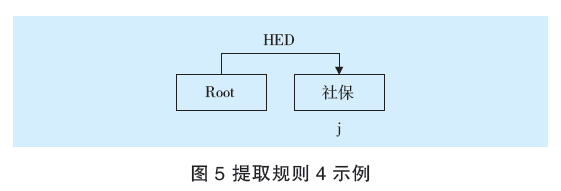
提取規則4示例如圖5所示,示例為提取交易標簽
2.2 業務標簽提取規則
由于交易業務往往會帶有明顯的關鍵詞,比如費、款、金等,因此業務標簽提取規則將圍繞這些關鍵字展開設計,思路是先定位業務詞,再識別業務動詞,具體如下。
2.2.1規則1
如果分詞結果中的詞能與關鍵詞庫中的詞完全匹配,則將該詞標記為H,根據句法分析結果找到與H有ATT關系的詞,記為ATTH。如果沒有ATT,則不能提取標簽。
然后從分詞結果中查找是否有詞包含業務動詞庫中的詞。
1)若沒有,則業務動詞默認為‘付’,記為V;
2)若只有1個,則該詞為業務動詞,將該詞記為V;
3)若有多個,則優先級最高的詞為業務動詞,若優先級相同,則按句法關系順序合并為1個業務動詞,記為V;如果V是ATTH+H的子字符串,業務標簽為+H;否則業務標簽為V++H。
規則1部分示例如表2所列。

2.2.2規則2
如果分詞結果中的詞包含關鍵詞庫中的詞(非完全匹配),則將該詞標記為H。
1)若H只有1個,業務動詞的查找規則與“規則1”一致。如果V是H的子字符串,則業務標簽為H,否則業務標簽為V+H;
2)若H有多個,則依次檢查與H詞語法關系為VOB的動詞:若能找到,且該動詞在業務動詞庫中,則該詞為業務動詞,否則默認業務動詞為“付”,記為V,業務標簽結果為V+H;若找不到,查找H中是否包含業務動詞庫中的詞,如果包含,則業務動詞為空,業務標簽為H,否則業務動詞默認為‘付’,記為V,業務標簽結果為V+H。
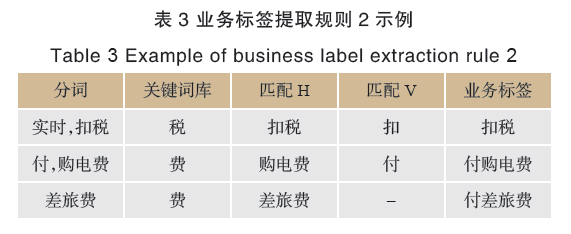
規則2部分示例見表3所列。
2.2.3規則3
如果分詞結果中的詞不包含關鍵詞庫中的詞,則不能提取業務標簽。
3 實證分析
3.1 數據來源
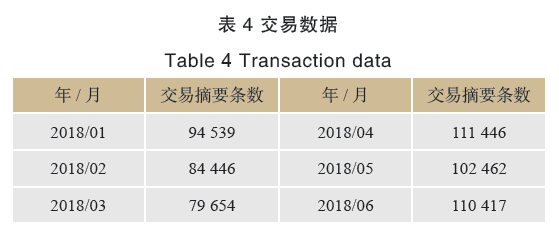
實證分析所用數據來自某電網公司2018年1月至6月的銀行交易流水數據(見表4)。
3.2 評價指標
本文使用精確率和召回率以及F-Measure對實證分析結果進行評估,同時將人工提取的標簽作為準確標簽結果。精確率是指算法提取結果中的正確標簽數占提取出的總標簽數的比例,召回率是指算法提取結果中正確標簽數與交易摘要中實際可提取標簽總數的比例。F-Measure則是綜合了精確率和召回率的評價指標。計算公式分別如下。
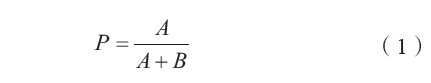
式中,P表示精確率,A表示可提取并且提取正確的標簽個數,B表示原本不可以提取標簽但提取的標簽個數以及提取錯誤的標簽個數之和。

式中,R表示召回率,C表示未能正確提取標簽的個數。
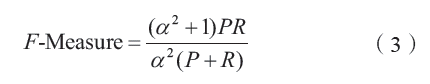
式中,α是用來衡量精確率和召回率的相對重要性的參數,本文將精確率和召回率視為同等重要,即α取值為1,故F-Measure故為F1:
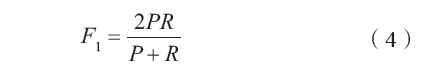
3.3 結果分析
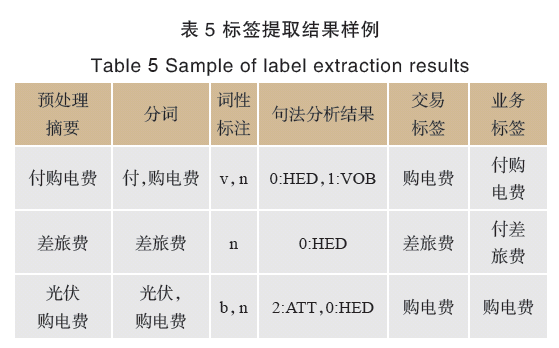
表5展示的是2018年6月銀行交易摘要提取標簽的部分結果。
3.3.1 模型精確率與召回率分析
考慮到每月提取標簽的數量級大約在10萬條,數量較多,人工識別成本高,因此,本文將采取隨機抽樣方式,每次隨機抽取1000條交易摘要,將提取的標簽與基于人工提取標簽相比,計算模型的精確率、召回率和F1值。同時為了保證評價指標的可靠性,重復3次有放回抽樣,并用3次結果的均值作為模型最后的評價指標,標簽提取結果分析見表6所列。
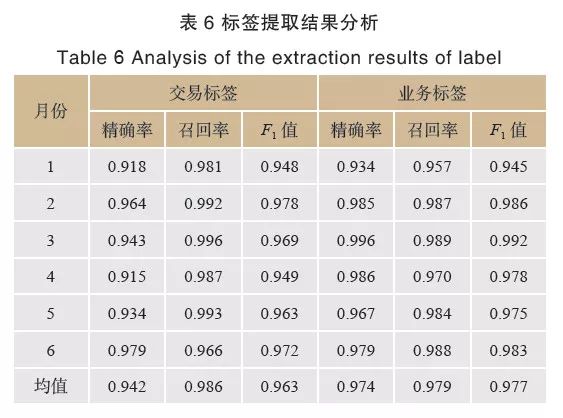
從結果分析表中可知,6個月的交易摘要的交易標簽和業務標簽提取精確率均在90%以上,部分月份達到98%,召回率均在95%以上,整體F1值超過94%。
精確率方面,交易標簽的精確率均較高,主要是因為本文的交易標簽的提取規則考慮全面并且業務同義詞庫相對完整。相比交易標簽,業務標簽的精確率相對更高,主要是因為提取規則更加開放,更能體現一般性。
召回率方面,交易標簽和業務標簽的召回率均很高,主要是因為摘要語句較短,句子的核心詞基本都具有業務含義詞語,因此召回率較高。6個月的召回率都比較高且比較穩定,說明提取規則可以識別出大部分的交易摘要,同時表明構建的業務同義詞庫和業務動詞庫比較全面。
綜上分析,模型整體效果很好,而且表現穩定。
3.3.2 影響模型效果因素分析
對實證結果中未能提取標簽或標簽提取錯誤的摘要進行歸納總結,主要原因如下。
(1)交易摘要過于簡單、語義不明。存在省略主語、錯別字、口語化及漏填等情況,例如
(2)分詞及詞性標注結果的準確性。由于電網企業涉及很多專業詞匯,在專業字典不完整的情況下,會發生切詞及詞性標注出錯的情況,導致無法準確提取標簽。
(3)詞庫的完整性。少部分摘要未能提取交易標簽是由于業務同義詞庫不完整導致的,另外,業務動詞庫和業務關鍵詞庫的完整性也在一定程度上影響了業務標簽的提取。
3.4 畫像展示
圖6、圖7分別展示了某一資金賬戶的交易標簽和業務標簽的提取效果。


4 結語
本文采用自然語言處理技術對電網企業銀行交易流水摘要進行挖掘分析,構建了資金賬戶交易畫像模型,突破了傳統的數據查詢分析對非結構化數據處理與應用的限制,能夠從更全面的角度了解賬戶的歷史交易特征,對未來新的交易行為是否存在異常具有重要的參考價值。
在對某電網公司近6個月的實證分析中,本模型獲得了平均96%以上的F1值,證實了模型的有效性和實用性,能夠在電網企業進行推廣應用。
針對影響模型效果的因素,本文考慮從以下幾方面做出改進:
①建立詞庫的完善機制。通過機制不斷沉淀業務專家的知識經驗,保持模型的有效性;
②進一步優化專業詞典。一方面建立類似于詞庫的完善機制,不斷加入專業詞匯;另一方面需要充分應用自然語言處理技術發現新詞的能力,從專業網站中提取新詞;
③規范交易摘要填寫。制定摘要規范性填寫指導說明書,將摘要的規范性納入績效考核中,通過管理手段,保證摘要的完整性和規范性。

 粵公網安備 44049102496133號
粵公網安備 44049102496133號